- Sometimes as a SQL developer, you might find a need to detect and remove duplicate records from a table. Duplicates often occur due to improper database design. There are quite a few methods of eliminating duplicate records. The method you decide to use typically would depend on the situation you are faced with. In this article, I will share two methods of removing duplicate records. The first method involves removing duplicate records from a table without a UniqueID while the second method involves removing duplicate records from a table with a UniqueID.
Method One: Removing Duplicates from a table without a UniqueID
This approach is typically suitable for not too large datasets and where database space is not a concern as it involves moving the distinct records into a temporary table, truncating the original table, and then moving the records from the temporary table back into the original table. Before we continue, let’s create our sample dataset:
CREATE TABLE [dbo].[Employee]( [FirstName] [varchar](20) NULL, [LastName] [varchar](20) NULL, [BirthDate] [date] NULL ) ON [PRIMARY] GO INSERT [dbo].[Employee] ([FirstName], [LastName], [BirthDate]) VALUES (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03'), (N'Amanda', N'Lopez', '1980-06-01'), (N'Adam', N'Smith', '1971-02-26'), (N'Taylor', N'Ramsey', '1984-03-01'), (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03'), (N'Amanda', N'Lopez', '1980-06-01'), (N'Adam', N'Smith', '1971-02-26'), (N'Taylor', N'Ramsey', '1984-03-01'), (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03')
Taking a closer look at the table below, you will realize there are some duplicate records. For example, employee John Brown appears three times in the table.
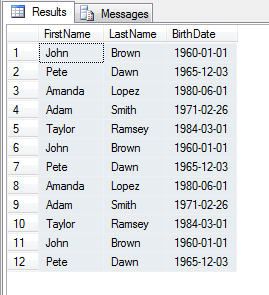
Steps
1. Select DISTINCT records into temporary table.
SELECT DISTINCT [FirstName], [LastName], [BirthDate] INTO #Employee
2. TRUNCATE original table
TRUNCATE TABLE dbo.Employee
3. Reinsert the records from the temporary table into the original table
INSERT INTO dbo.Employee SELECT * FROM #Employee
4. Now, you can check the original table to verify that the duplicate records are gone.
SELECT * FROM dbo.Employee
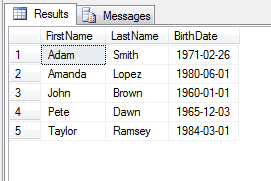
You will notice that in our original dataset, we had 12 rows of data, this has been reduced to just 5 rows because we have been able to remove the duplicate records.
The above method is typically suitable for not too large dataset and where space is not much of a concern. You can also replace the temporary table with a permanent table to reduce the risk of losing all the data if you close out of the session.
Method Two: Removing duplicates from a table with a UniqueID
This approach is my most preferred since most tables will contain some kind of uniqueID anyways. To demonstrate this method, I will be recreating the employee table (feel free to drop or rename the table we created in the first step). In this new table we’ll be creating, we’ll add an identity column, which will serve as our uniqueID.
CREATE TABLE [dbo].[Employee]( [EmpID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [varchar](20) NULL, [LastName] [varchar](20) NULL, [BirthDate] [date] NULL ) ON [PRIMARY] GO INSERT [dbo].[Employee] ([FirstName], [LastName], [BirthDate]) VALUES (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03'), (N'Amanda', N'Lopez', '1980-06-01'), (N'Adam', N'Smith', '1971-02-26'), (N'Taylor', N'Ramsey', '1984-03-01'), (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03'), (N'Amanda', N'Lopez', '1980-06-01'), (N'Adam', N'Smith', '1971-02-26'), (N'Taylor', N'Ramsey', '1984-03-01'), (N'John', N'Brown', '1960-01-01'), (N'Pete', N'Dawn', '1965-12-03')

Looking at the resultset above, you will realize that using a SELECT DISTINCT does not eliminate the duplicates. This is because all the records are unique due to the uniqueID. To handle this, we’ll use one of the ranking functions called the ROW_NUMBER() as well as a Common Table Expression (CTE).
Steps:
1. Create a CTE called Emp_CTE
WITH Emp_CTE (EmpID, FirstName, LastName, BirthDate, RecordCount) --Specify the column list for the CTE AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY FirstName, LastName, BirthDate ORDER BY FirstName) AS RecordCount FROM dbo.Employee ) SELECT * FROM Emp_CTE
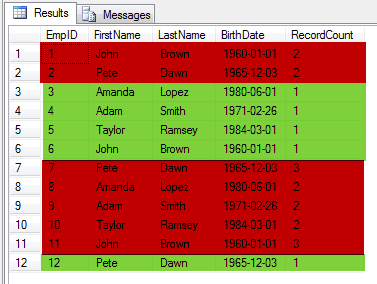
You will notice that there is a new derived column called RecordCount. This column tells us the number of times a similar set of records appear in the table. If you look at the resultset below, if are only interested in the records with RecordCount = 1 (highlighted in yellow). The rest of the records (highlighted in red) need to go because they are duplicate records.
2. DELETE the duplicate records from the CTE
I will run the above CTE again but this time, instead of a SELECT statement, I will be performing a DELETE operation on the records that appear more than once.
WITH Emp_CTE (EmpID, FirstName, LastName, BirthDate, RecordCount AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY FirstName, LastName, BirthDate ORDER BY FirstName) AS RecordCount FROM dbo.Employee ) DELETE FROM Emp_CTE WHERE RecordCount > 1
3. Run a SELECT statement to verify that the duplicates are gone
SELECT * FROM dbo.Employee
From the resultset below, notice that the duplicates are all gone now.

Summary
Delete operations can be expensive, so it might be helpful to avoid duplicates in the first place by making sure that there are proper constraints and relationships on your database tables when creating your tables. If you like what you read or if you have some suggestions, kindly comment on the post, I’d be very happy to hear from you. You can also visit www.eklipseconsult.com if you want to learn more on SQL Server and Business Intelligence.
Thanks for reading!




For the first option (no identity column) I would move distinct rows to a permanent table. Drop original table. Rename new table to original table.
The second scenario should never be encountered in a DWH since Fact tables are linked to the DIM tables by this identity column. Thus if we delete rows from the DIM table we will end up with orphaned rows in the Fact tables. Also the Fact tables should not use FK for performance considerations. All should carefully be handled through well planned ETL.
Anyway for the sake of discussion I would handle this the same way as for option 1 only that I will be using SSIS in order to make it simple.